TECHNOLOGY
Cutting-edge Computer Vision technology is the heart of our company.
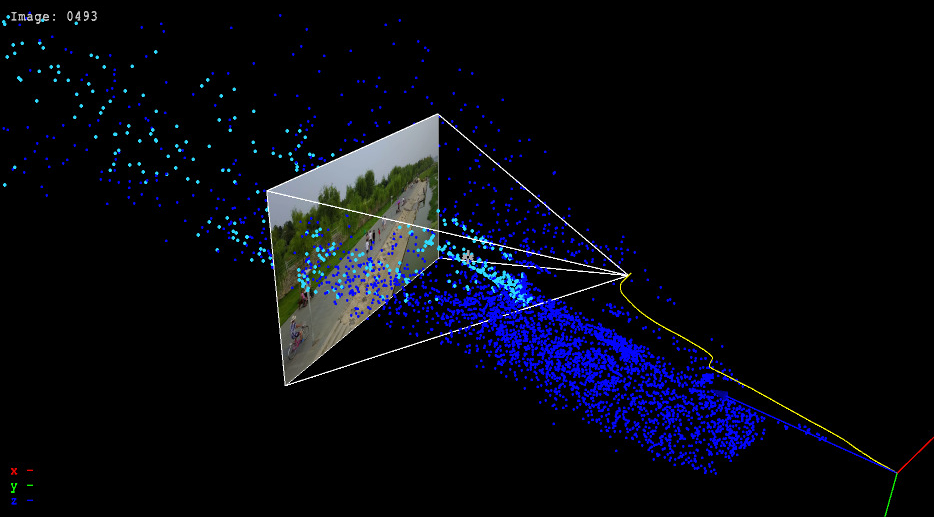
Scene Reconstruction from Video
Our bread and butter is the retrieval of 3D information from images using simultaneous localization and mapping (SLAM) and structure from motion (SfM) techniques. Our algorithms allow to reconstruct 3D scenes and camera motion from any image sequence captured with devices such as GoPros, smartphones, or integrated cameras of modern vehicles.


Building Reconstruction and Modeling
Automated recording, digitization, classification, and structuring of building surfaces
- Building information modeling (BIM)
- Reconstruction from camera images
- Semantic segmentation of images and pointclouds
- Focus on facades: Digi-PV project

Dataset Construction: Interactive Tools for Automated 2D/3D-Annotation
For new, vision-based AI tasks, special annotation of image content is required.
We develop flexible, semi-automatic toolchains for the targeted tasks.
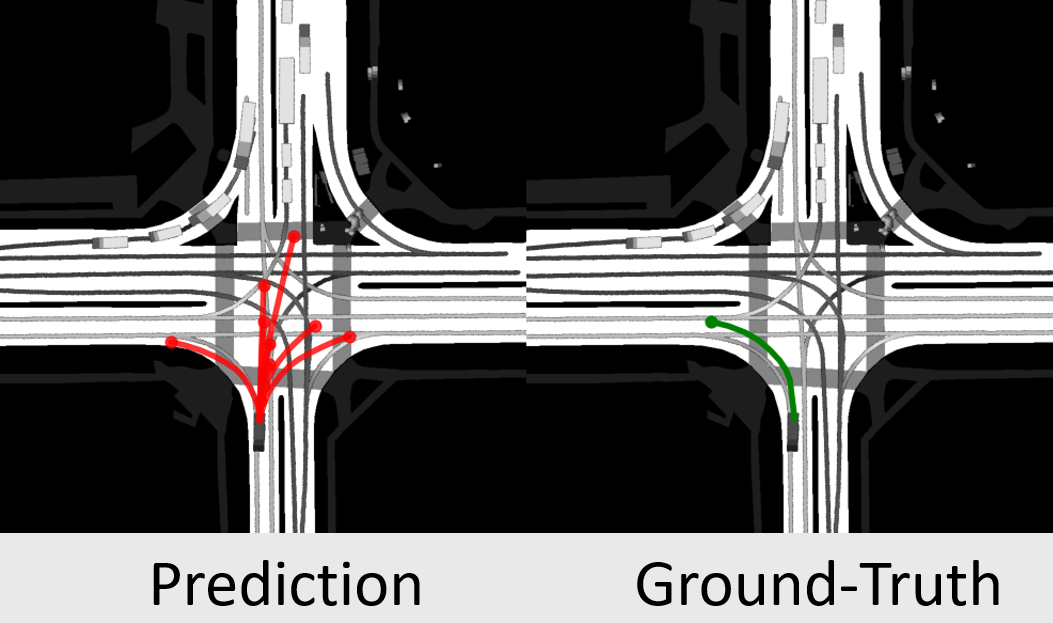
Trajectory Prediction
Based on past trajectories, we predict the most probable future behaviour of objects.
Our model provides multiple diverse and realistic future trajectories using an efficient, real-time capable AI approach.
- Trajectory prediction flyer
- GATraj: A Graph- and Attention-based Multi-Agent Trajectory Prediction Model
- LAformer: Trajectory Prediction for Autonomous Driving with Lane-Aware Scene Constraints

Road Condition Estimation
For the camera-based determinination of the current road condition, classification and uncertainty estimation using machine learning is incorporated.
Never give up your steering wheel without knowing the road condition!
- InFusion poster
- Demonstration video [youtube]
- Check our datasets
- RoadSaW dataset for Road Surface and Wetness estimation
- RoadSC: Road Snow Coverage dataset
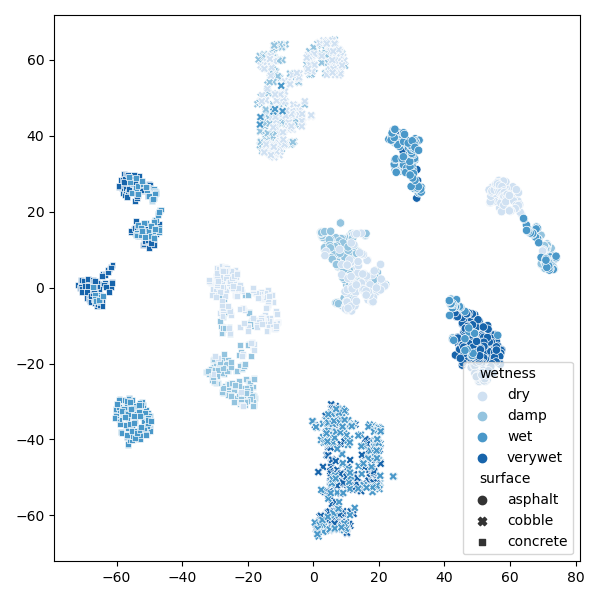
Uncertainty Estimation in Deep Learning
Many applications rely on computer vision models based on deep learning.
Predictions from these models are subject to uncertainty due to limited learning data.
How sure are these models in their prediction? - We employ models for uncertainty which provide valid estimations for data which is not whithin the learning dataset distribution.
- Application example: "RoadSaW: A Large-Scale Dataset for Camera-Based Road Surface and Wetness Estimation", paper at CVF, paper at ieeexplore

Object Motion Estimation
- Panoptic video segmentation
- Variational approaches for video and motion segmentation
- RANSAC and hypergraph based hypothesis generation
- AI based localization, tracking, and classification
- Vehicle localization demonstration video, 5GCAR project [youtube]
- VLMV: dataset for vehicle localization and maneuver planning
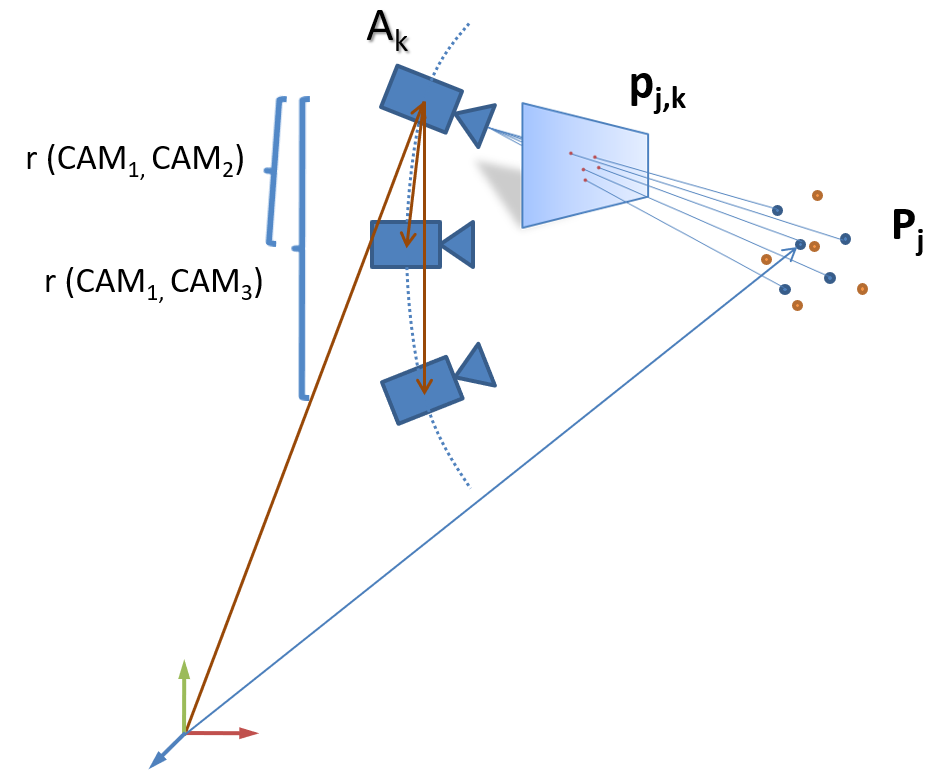
Camera Calibration
- Guided calibration: computation of camera parameters using known calibration patterns for individual cameras and multi-camera setups
- Registration: estimation of camera parameters based on known 3D geometry.
- Self-calibration: optimization of calibration during acquisition. Automatically selected image features provide calibration landmarks.

Stereo
Depth-from-stereo has become ever more relevant over the last few years since more stereo cameras are integrated into smartphones and modern vehicles. We develop algorithms to produce accurate depth maps from stereo image pairs using dense matching, optical flow, and machine learning approaches. Additionally, we provide
- Calibration accuracy control: measurement of current calibration accuracy
- Self-calibration: optimization of stereo calibration during acquisition.
- NEW: paper published
- "Accuracy Evaluation and Improvement of the Calibration of Stereo Vision Datasets", ECCV - VCAD workshop, 2024, pdf
- Method provides calibration accuracy measurement + online calibration
- Results Demonstration [YouTube]

Point Cloud Processing
As a result from reconstruction techniques, point clouds and meshes are used for 3D model generation. 3D models have measurable attributes, such as size, shape, and distances to other models. These attributes enable applications, e.g., for obstacle detection in automated driving scenarios. Object clustering and fitting provides the identification based on 3D points and specific models.

Semantic Scene Reconstruction
- Machine learning techniques: powerful real-time performance for dedicated tasks, such as object detection, classification, and segmentation
- Deep learning: large scale optimization for reference results
- Data set generation: developing tools for automatic augmentation and semi-automatic ground truth generation.
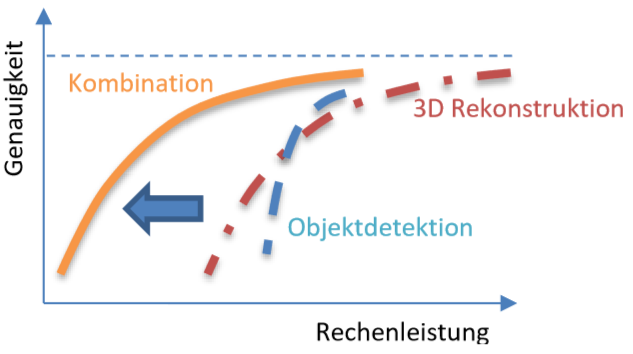
Resource Adaptive Scene Analysis and Reconstruction
Some of these techniques were developed as part of the RaSar research project.